When Your Safety Margin Isn’t: A Datacenter Post-Mortem
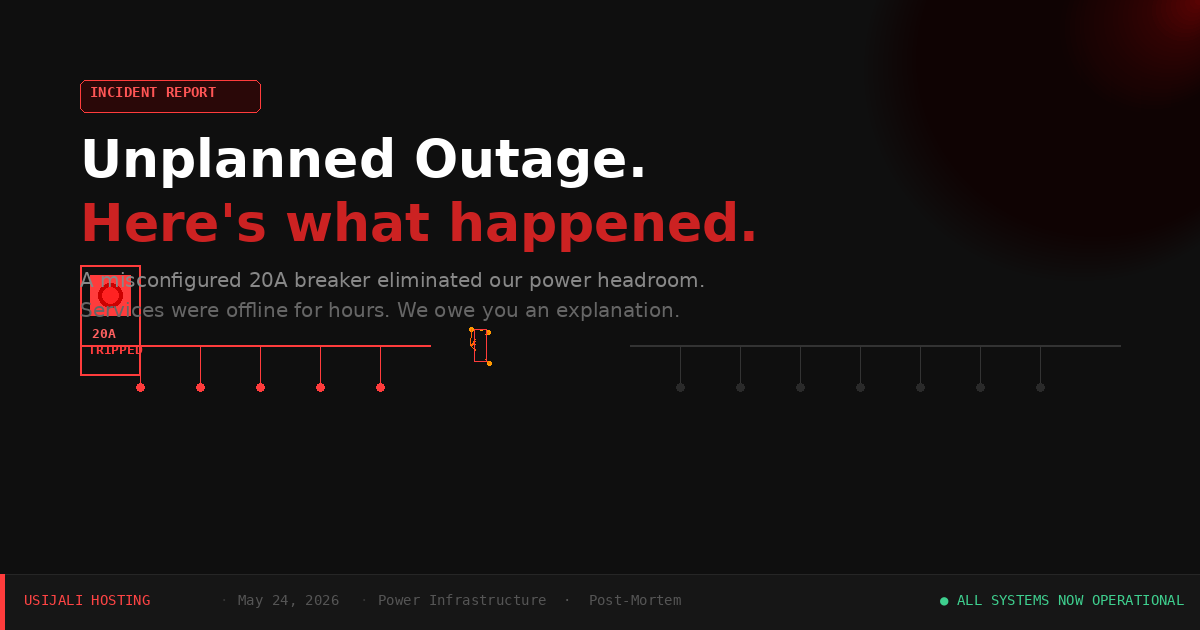
Unplanned Service Outage — Power Infrastructure Failure
Late yesterday, Usijali Hosting experienced an unplanned outage that took hosted services offline for several hours. We owe you a full, honest account of what happened — and a direct apology for the time it took us to say anything at all. You deserved faster communication, and we failed to provide it.
This post covers the root cause in technical detail, our accountability around the communications failure, and the concrete steps we are taking on both fronts.
What Happened
The outage was caused by a tripped breaker on our CyberPower PDU (power distribution unit) strips inside the datacenter. These strips are equipped with a physical safety mechanism — two red pop-out breaker buttons — that cut power when electrical load exceeds their rated threshold. That mechanism did exactly what it was designed to do. The problem was that we did not have the capacity headroom we believed we had.
Industry best practice — and fire code in the US and EU — requires running power infrastructure at no more than 80% of rated capacity. That 20% buffer exists specifically to absorb transient spikes and surges without tripping breakers. We believed we were comfortably within that envelope.
What we did not know was that our PDU strips were sitting on 20A breakers, not the 30A breakers we had been planning around. That 10A gap quietly erased the headroom we thought we had. When a brief power spike hit — the kind that is routine in any active datacenter environment, lasting only milliseconds — there was no buffer left to absorb it.
It is worth understanding how breakers work in this context. Every breaker has a rated tolerance: a window measured in milliseconds during which it can handle an overcurrent event before it trips. Exceeding 16A on a 16A breaker for a few milliseconds may be fine; sustaining that overcurrent trips it. Our 20A breakers, already running close to their real ceiling due to the misconfiguration, had no tolerance left when the spike hit. The breakers tripped, the pop-out buttons fired, and services went down.
Why You Didn't Hear From Us Sooner
This is the part we are most accountable for. Services were offline for hours before we published any public acknowledgment. While our team was working to diagnose and restore power, our incident communications process failed to activate in parallel.
The correct standard is simple: the moment we know something is wrong, you should know too. Not once we understand the cause. Not once we have an ETA. Not once services are back. The moment. We did not meet that standard today, and there is no satisfactory explanation for it — only an acknowledgment that it was wrong and a commitment to fix it.
Incident Timeline
Transient power spike in the datacenter. CyberPower PDU breakers trip. Hosted services go offline.
On-call team begins diagnosing. Root cause not yet identified. No public communication posted — this was the failure.
Datacenter team identifies 20A vs. 30A breaker discrepancy as the underlying cause. Power restoration begins.
All services fully restored. Remediation plan confirmed with datacenter. This incident report published.
We are working to confirm exact timestamps and will update this post when available.
What We Are Doing About It
We have a clear remediation path agreed with our datacenter team, and it covers both the hardware failure and the process failure.
- 01 Breaker replacement. The 20A breakers will be replaced with correctly rated hardware, restoring the power headroom we need to run safely within our 80% operating budget and absorb transient spikes.
- 02 PDU strip replacement. The CyberPower strips will be swapped out at the same time as the breaker work. Both jobs will be done in a single coordinated maintenance window.
-
03
Zero additional downtime for this repair. Our infrastructure runs on redundant
A+Bpower feeds. The datacenter team will work on each leg independently, keeping services live throughout. This is a manageable lift and we are confident in the approach. - 04 Incident communications overhaul. We are revising our on-call runbook to ensure a public status update is posted within minutes of any service-affecting event being detected — before root cause, before resolution, before we have complete information. Silence is not acceptable.
- 05 Power infrastructure audit. We are conducting a full audit of breaker ratings across all PDU strips to ensure what we believe about our infrastructure matches reality. Today's incident exposed a dangerous assumption we did not know we were making.
Closing
This outage should not have happened, and the silence that surrounded it made a bad situation worse. We take both seriously. The infrastructure fix is straightforward; the process fix requires discipline, and we are committed to holding ourselves to it.
If you are still experiencing any issues following the restoration, please contact our support team and we will make it right.
With accountability,
The Usijali Hosting Infrastructure Team
May 24, 2026



Post Comment